 20.01.2024, 11:25
20.01.2024, 11:25
|
#6161
|
|
Почётный гражданин KAZUS.RU
Регистрация: 27.01.2005
Адрес: Россия, КЧР, Нижний Архыз
Сообщений: 3,627
Сказал спасибо: 115
Сказали Спасибо 814 раз(а) в 591 сообщении(ях)

|
 Re: Изучаем STM32 Cortex M3
Re: Изучаем STM32 Cortex M3
ankirus, а что, руками написать Makefile - не судьба?
__________________
Союз Советских Социалистических Округов Северной Америки
|

|

|
|
|
20.01.2024, 13:13
|
#6162
|
|
Частый гость
Регистрация: 30.05.2009
Сообщений: 25
Сказал спасибо: 2
Сказали Спасибо 1 раз в 1 сообщении
|
Re: Изучаем STM32 Cortex M3
штук так под тридцать субдиректорий
__________________
"При отрыве шестой ноги таракан теряет слух"
|
|
|
|
|
|
20.01.2024, 13:43
|
#6163
|
|
Почётный гражданин KAZUS.RU
Регистрация: 27.01.2005
Адрес: Россия, КЧР, Нижний Архыз
Сообщений: 3,627
Сказал спасибо: 115
Сказали Спасибо 814 раз(а) в 591 сообщении(ях)
|
Re: Изучаем STM32 Cortex M3
Сообщение от ankirus

|
|
тридцать субдиректорий
|
Вот не поверю, что они все используются! Из внешних поддиректорий нужны только CMSIS, стартап и линкер. Ну, кто-то может свои наработки в отдельное дерево выделить. А больше и нечего! Откуда там 30?
Но даже такое можно средствами make провернуть, не переписывая все вручную. Или башем сгенерить ☺
__________________
Союз Советских Социалистических Округов Северной Америки
|
|
|
|
|
|
20.01.2024, 13:48
|
#6164
|
|
Заблокирован
Регистрация: 07.09.2014
Адрес: В Кремле!
Сообщений: 4,486
Сказал спасибо: 396
Сказали Спасибо 2,220 раз(а) в 1,319 сообщении(ях)
|
Re: Изучаем STM32 Cortex M3
Если имеете ввиду именно CubeMX, а не CubeIDE, то генератор конфигурации CubeMX генерирует код на языке Си. Но сам С++ запросто переваривает язык Си, ведь это его прямой предок. Поэтому, поместив сгенерированные исходники в проект С++ и подключив их, прописав пути до папок, всё должно получиться.
С другой стороны, неясно, какие сложности вызывает стандартная библиотека шаблонов STL? Одно с другим совсем не связано. Куб генерирует конфигурацию МК, а STL является частью (дополнением) языка С++. И из этого дополнения используются такие инсрументы, как вектор, контейнер, циклы на основе диапазона и прочее тому подобное. Использование этих инструментов требует подключения заголовочных файлов от них самих. Например, если создаете вектор, нужно подключить #include ‹vector›, а так же не забывать, что инструментарий векторов находится в пространстве имен std, значит надо его using namespase std; или же std::vectcor ...
|
|
|
|
|
|
22.01.2024, 20:55
|
#6165
|
|
Частый гость
Регистрация: 30.05.2009
Сообщений: 25
Сказал спасибо: 2
Сказали Спасибо 1 раз в 1 сообщении
|
Re: Изучаем STM32 Cortex M3
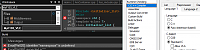
Спасибо. Коротко, суть проблемы в том, что в сгенерированный CUBERMX сишный код IAR не хочет добавлять С++, несмотря на правильное расширение cpp, hpp и несмотря на опцию "auto" на вклaдке compiller-›Language1 , и независимо, что стоит в выпадaющем меню Library: Libc++ или что-то еще. IAR установлен - 930. Подскажите, у меня одного так? Ничего не нашел в инете на эту тему.
Если начинать новый проект в IARe через меню Project -› create new project, то c c++ все нормально, даже отлично, но тогда инициализацию CUBEMX никак не получается использовать - вылезают разные ошибки компиляции.
|
|
|
|
|
|
19.02.2024, 16:39
|
#6166
|
|
Почётный гражданин KAZUS.RU
Регистрация: 24.03.2007
Сообщений: 1,359
Сказал спасибо: 85
Сказали Спасибо 613 раз(а) в 371 сообщении(ях)
|
Re: Изучаем STM32 Cortex M3
Возник вопрос по передаче данных через IN endpoint.
Если передаю значение меньше или равное размеру EP - все ок (ZLP тоже не забываю, если размер данных равен размеру EP).
Но возникает проблема с IN через EP типа Interrupt, если размер данных более чем размер EP. Хост (Win10) принимает данные не цельным куском, а кусками по размеру EP. Т.е., если размер EP 8 байт, то пакет данных 12 байт принимается как два куска - по 8 и 4 байта.
С EP типа Bulk такой проблемы нет - данные видятся хостом как цельный кусок.
Куда копать?
Или транзакция USB interrupt может состоять только из одного пакета? Прямого указания на это в интернетах не нашел. Нашел только, что максимальный размер пакета для interrupt USB FullSpeed 64 байта.
Последний раз редактировалось pambaru; 19.02.2024 в 17:19.
|
|
|
|
|
|
19.02.2024, 18:22
|
#6167
|
|
Почётный гражданин KAZUS.RU
Регистрация: 24.03.2007
Сообщений: 1,359
Сказал спасибо: 85
Сказали Спасибо 613 раз(а) в 371 сообщении(ях)
|
Re: Изучаем STM32 Cortex M3
Итак, вроде нашел ответ. Если кому интересно:
Источник: "Universal Serial Bus Specification, Revision 2.0".
В главе "5.7.3 Interrupt Transfer Packet Size Constraints" читаем:
|
Цитата:
|
An endpoint must always transmit data payloads with a data field less than or equal to the endpoint’s wMaxPacketSize value.
A device can move data via an interrupt pipe that is larger than wMaxPacketSize.
A software client can accept this data via an IRP for the interrupt transfer that requires multiple bus
transactions without requiring an IRP-complete notification per transaction. This can be achieved by specifying a buffer that can hold the desired data size. The size of the buffer is a multiple of wMaxPacketSize with some remainder. The endpoint must transfer each transaction except the last as
wMaxPacketSize and the last transaction is the remainder. The multiple data transactions are moved over
the bus at the period established for the pipe.
When an interrupt transfer involves more data than can fit in one data payload of the currently established
maximum size, all data payloads are required to be maximum-sized except for the last data payload, which
will contain the remaining data. An interrupt transfer is complete when the endpoint does one of the
following:
• Has transferred exactly the amount of data expected
• Transfers a packet with a payload size less than wMaxPacketSize or transfers a zero-length packet
When an interrupt transfer is complete, the Host Controller retires the current IRP and advances to the next IRP.
|
В главе: "5.8.3 Bulk Transfer Packet Size Constraints" читаем:
|
Цитата:
|
An endpoint must always transmit data payloads with a data field less than or equal to the endpoint’s reported wMaxPacketSize value. When a bulk IRP involves more data than can fit in one maximum-sized data payload, all data payloads are required to be maximum size except for the last data payload, which will contain the remaining data. A bulk transfer is complete when the endpoint does one of the following:
• Has transferred exactly the amount of data expected
• Transfers a packet with a payload size less than wMaxPacketSize or transfers a zero-length packet
When a bulk transfer is complete, the Host Controller retires the current IRP and advances to the next IRP.
|
Т.е., "они оба могут (С)".
Тогда почему же не прокатывало у меня? Отвечаю:
|
Цитата:
|
|
This can be achieved by specifying a buffer that can hold the desired data size. The size of the buffer is a multiple of wMaxPacketSize with some remainder.
|
Т.е. в запросе должен быть соответствующий размер буфера.
А в моем случае, т.к. софтина сторонняя и я не управляю размером буфера, софт выделял размер буфера размером именно wMaxPacketSize (это отображалось в сниффере, но я не обратил внимания). Поэтому за одну транзакцию считывалось максимум wMaxPacketSize.
Может для кого-то будет полезной инфа.
|
|
|
|
|
 Ваши права в разделе
Ваши права в разделе
|
Вы не можете создавать новые темы
Вы не можете отвечать в темах
Вы не можете прикреплять вложения
Вы не можете редактировать свои сообщения
HTML код Выкл.
|
|
|
Часовой пояс GMT +4, время: 21:17.
|
|








